Sanity
Building an AI-Powered Knowledge Base with Next.js and Sanity
Learn how to build an AI knowledge base with Next.js and Sanity—combining vector search, LLMs, and structured content for intelligent, always-current developer documentation.

If you've ever wished your documentation could answer questions instead of just sitting there, you're in the right place. In this tutorial, you'll build a fully functional AI knowledge base with Next.js — one that ingests structured content from Sanity, indexes it into a vector database, and lets users query it using natural language powered by an LLM. By the end, you'll have a production-ready foundation for intelligent developer docs, internal wikis, or customer support portals.
What is an AI Knowledge Base
A traditional knowledge base is a collection of articles, guides, and FAQs that users search with keywords. An AI knowledge base goes further: it understands the meaning behind a query, retrieves the most semantically relevant content, and synthesizes a coherent answer — even when the user's phrasing doesn't match any document title.
The core technique is Retrieval-Augmented Generation (RAG). Content is chunked and converted into vector embeddings. A user query is also embedded into the same vector space. The nearest-neighbor chunks are retrieved, and an LLM generates a grounded answer from those chunks. This keeps answers accurate and up-to-date because the LLM always reads from your actual content — not from training data.
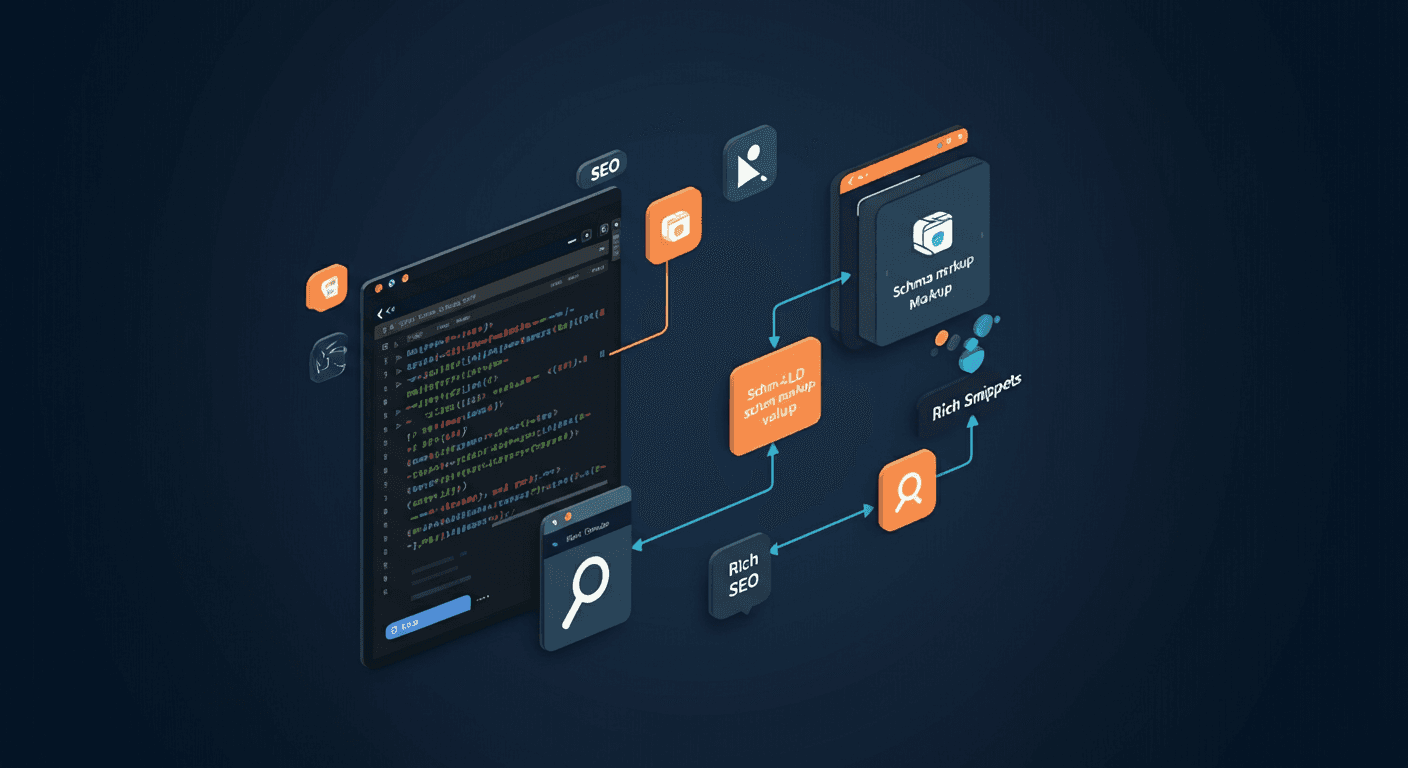
Architecture Overview
The stack combines four well-matched tools: Sanity as the structured content platform and source of truth; Next.js as the full-stack React framework handling both the editorial UI and API routes; Pinecone (or any vector DB) for storing and retrieving embeddings at scale; and OpenAI for generating embeddings (text-embedding-3-small) and answers (gpt-4o).
Here's how the pieces fit together at runtime. An editor publishes or updates an article in Sanity Studio. A Sanity webhook fires, triggering a Next.js API route (/api/index). That route fetches the article via GROQ, chunks the content, generates embeddings, and upserts them into Pinecone with the Sanity document ID as metadata. When a user asks a question, the /api/query route embeds the question, retrieves the top-k chunks from Pinecone, fetches source documents from Sanity, and streams a grounded answer from the LLM alongside source citations.
This architecture keeps Sanity as the single source of truth. The vector DB is a derived index, not a primary store — a critical distinction for content governance and auditability.
Setting Up Content Structure in Sanity
Define a knowledgeArticle document type in your Sanity schema. This drives both the editorial experience and the shape of data you'll index.
sanity/schemas/knowledgeArticle.ts:
import { defineType, defineField } from 'sanity'
export const knowledgeArticle = defineType({
name: 'knowledgeArticle',
title: 'Knowledge Article',
type: 'document',
fields: [
defineField({
name: 'title',
type: 'string',
validation: (Rule) => Rule.required().max(100),
}),
defineField({
name: 'slug',
type: 'slug',
options: { source: 'title', maxLength: 96 },
validation: (Rule) => Rule.required(),
}),
defineField({
name: 'category',
type: 'string',
options: {
list: ['getting-started', 'api-reference', 'troubleshooting', 'guides'],
},
}),
defineField({ name: 'body', type: 'array', of: [{ type: 'block' }] }),
defineField({ name: 'updatedAt', type: 'datetime' }),
],
})
Configure the Sanity client for server-side use with useCdn: false so indexing always reads fresh content:
lib/sanity.ts:
import { createClient } from '@sanity/client'
import { PortableTextBlock } from '@portabletext/types'
export const sanityClient = createClient({
projectId: process.env.NEXT_PUBLIC_SANITY_PROJECT_ID!,
dataset: process.env.NEXT_PUBLIC_SANITY_DATASET!,
apiVersion: '2024-01-01',
useCdn: false,
token: process.env.SANITY_API_TOKEN,
})
export type KnowledgeArticle = {
_id: string
title: string
slug: { current: string }
category: string
body: PortableTextBlock[]
updatedAt: string
}
Indexing Knowledge Base Content
Indexing has two phases: converting Portable Text to plain text, then chunking and embedding it. Install the required packages first:
npm install @portabletext/to-plain-text openai @pinecone-database/pinecone
Create a utility to serialize Portable Text and chunk it into overlapping windows (lib/serialize.ts):
import { toPlainText } from '@portabletext/to-plain-text'
import { PortableTextBlock } from '@portabletext/types'
export function serializeBlocks(blocks: PortableTextBlock[]): string {
return toPlainText(blocks)
}
export function chunkText(
text: string,
chunkSize = 500,
overlap = 50
): string[] {
const words = text.split(/\s+/)
const chunks: string[] = []
for (let i = 0; i < words.length; i += chunkSize - overlap) {
chunks.push(words.slice(i, i + chunkSize).join(' '))
if (i + chunkSize >= words.length) break
}
return chunks
}
Now create the indexing API route (app/api/index/route.ts). This is triggered by a Sanity webhook on every publish event:
import { NextRequest, NextResponse } from 'next/server'
import { sanityClient, KnowledgeArticle } from '@/lib/sanity'
import { serializeBlocks, chunkText } from '@/lib/serialize'
import OpenAI from 'openai'
import { Pinecone } from '@pinecone-database/pinecone'
const openai = new OpenAI({ apiKey: process.env.OPENAI_API_KEY })
const pinecone = new Pinecone({ apiKey: process.env.PINECONE_API_KEY! })
const index = pinecone.index(process.env.PINECONE_INDEX_NAME!)
export async function POST(req: NextRequest) {
const { _id } = await req.json()
const article = await sanityClient.fetch<KnowledgeArticle>(
`*[_type == "knowledgeArticle" && _id == $id][0]`,
{ id: _id }
)
if (!article) return NextResponse.json({ error: 'Not found' }, { status: 404 })
const chunks = chunkText(serializeBlocks(article.body))
const { data } = await openai.embeddings.create({
model: 'text-embedding-3-small',
input: chunks,
})
await index.upsert(
data.map((e, i) => ({
id: `${article._id}-chunk-${i}`,
values: e.embedding,
metadata: {
articleId: article._id,
title: article.title,
slug: article.slug.current,
category: article.category,
text: chunks[i],
},
}))
)
return NextResponse.json({ indexed: chunks.length })
}
Building the AI Query Interface
The query route embeds the user's question, retrieves relevant chunks from Pinecone, fetches source articles from Sanity, and streams an answer from the LLM. Create app/api/query/route.ts:
import { NextRequest } from 'next/server'
import { OpenAIStream, StreamingTextResponse } from 'ai'
import OpenAI from 'openai'
import { Pinecone } from '@pinecone-database/pinecone'
import { sanityClient } from '@/lib/sanity'
const openai = new OpenAI({ apiKey: process.env.OPENAI_API_KEY })
const pinecone = new Pinecone({ apiKey: process.env.PINECONE_API_KEY! })
const index = pinecone.index(process.env.PINECONE_INDEX_NAME!)
export async function POST(req: NextRequest) {
const { question } = await req.json()
// 1. Embed the question
const { data } = await openai.embeddings.create({
model: 'text-embedding-3-small',
input: question,
})
// 2. Retrieve top-5 semantically relevant chunks
const results = await index.query({
vector: data[0].embedding,
topK: 5,
includeMetadata: true,
})
const chunks = results.matches.map((m) => m.metadata?.text as string)
const articleIds = [
...new Set(results.matches.map((m) => m.metadata?.articleId as string)),
]
// 3. Fetch source titles for citations
const sources = await sanityClient.fetch(
`*[_id in $ids]{ _id, title, "url": "/kb/" + slug.current }`,
{ ids: articleIds }
)
// 4. Stream the grounded answer
const response = await openai.chat.completions.create({
model: 'gpt-4o',
stream: true,
messages: [
{
role: 'system',
content: 'Answer using only the provided context. If the answer is not present, say so.',
},
{
role: 'user',
content: `Context:\n${chunks.join('\n\n---\n\n')}\n\nQuestion: ${question}`,
},
],
})
return new StreamingTextResponse(OpenAIStream(response), {
headers: { 'X-Sources': JSON.stringify(sources) },
})
}
On the frontend, use the Vercel AI SDK's useChat hook to wire up the streaming UI (app/knowledge-base/page.tsx):
'use client'
import { useChat } from 'ai/react'
export default function KnowledgeBasePage() {
const { messages, input, handleInputChange, handleSubmit, isLoading } =
useChat({ api: '/api/query' })
return (
<main className="max-w-2xl mx-auto p-6">
<h1 className="text-2xl font-bold mb-4">Knowledge Base</h1>
<div className="space-y-4 mb-6">
{messages.map((m) => (
<div key={m.id} className={m.role === 'user' ? 'text-right' : ''}>
<p className="inline-block bg-gray-100 rounded px-3 py-2">
{m.content}
</p>
</div>
))}
</div>
<form onSubmit={handleSubmit} className="flex gap-2">
<input
value={input}
onChange={handleInputChange}
placeholder="Ask a question..."
className="flex-1 border rounded px-3 py-2"
/>
<button type="submit" disabled={isLoading}
className="bg-blue-600 text-white px-4 py-2 rounded">
Ask
</button>
</form>
</main>
)
}
Keeping the Knowledge Base Updated
Stale embeddings are one of the most common failure modes in RAG systems. Sanity Webhooks are the primary mechanism: configure them in your Sanity project settings to fire on create, update, and delete events for knowledgeArticle documents. For delete events, add a /api/deindex route that calls index.deleteMany({ filter: { articleId: _id } }).
Complement webhooks with a daily cron job (via Vercel Cron or GitHub Actions) that queries Sanity for articles updated in the last 24 hours and re-indexes only those. Also version your embeddings by storing a modelVersion field in Pinecone metadata. When you upgrade embedding models, you can filter out stale vectors and re-index in the background without downtime. Monitor average similarity scores over time — a sustained drop signals that your content has diverged from the indexed embeddings.
Common Mistakes
Chunking too coarsely. Chunks of 2,000+ words often include irrelevant content that dilutes retrieved context. Aim for 300–600 words with a small overlap.
Skipping overlap. Without overlap between chunks, sentences at chunk boundaries lose their surrounding context. A 10% overlap is a reliable starting point.
Using CDN-cached Sanity responses for indexing. Always set useCdn: false in your Sanity client when fetching content for indexing. Stale CDN responses will cause your index to lag behind published content.
Not validating webhook payloads. Anyone who knows your /api/index URL can trigger re-indexing. Always validate the sanity-webhook-signature header in production.
Sending the entire document as context. Passing 10,000 words to the LLM is expensive and often counterproductive. Trust your retrieval step — send only the top-k chunks. Also count tokens before sending and truncate if necessary to avoid hitting the model's context window limit.
Best Practices
Use structured metadata aggressively. Store category, slug, title, and updatedAt in Pinecone metadata so you can filter queries by category or date without an extra Sanity round-trip.
Implement a feedback loop. Log which chunks were retrieved for each query and whether the user rated the answer positively. Use this data to identify content gaps and improve your chunking strategy over time.
Cache embeddings for common queries. Use Redis or Vercel KV to cache top-k results for frequently asked questions. This reduces latency and OpenAI API costs significantly.
Separate indexing from serving. Run your indexing pipeline as a background job, not inline with the webhook response. This prevents timeouts on large articles and keeps your API routes fast.
Test retrieval quality independently. Before evaluating answer quality, evaluate retrieval quality: for a set of known questions, does the correct chunk appear in the top-5 results? Fix retrieval before tuning prompts.
Use namespace isolation in Pinecone. If you serve multiple products or tenants, use Pinecone namespaces to isolate their vectors. This prevents cross-contamination and makes cleanup trivial.
FAQ
Do I need a paid OpenAI plan to build this?
The free tier is sufficient for development and low-traffic production use. text-embedding-3-small is very affordable at $0.02 per million tokens. For high-traffic production, budget for both embedding and chat completion costs and consider caching aggressively.
Can I use a different vector database instead of Pinecone?
Yes. The architecture is database-agnostic. Popular alternatives include Weaviate, Qdrant, pgvector (if you're already on PostgreSQL), and Supabase Vector. The indexing and query logic is nearly identical — only the client SDK changes.
How do I handle Sanity's Portable Text in the embeddings?
Use @portabletext/to-plain-text to serialize blocks to plain text before chunking. This strips formatting marks and image blocks, leaving clean prose that embeds well. For code blocks, you may want to include them verbatim since they carry semantic meaning.
What's the best way to cite sources in the AI answer?
Pass source metadata (title, URL) alongside the context in the system prompt and instruct the model to cite sources using a consistent format. Alternatively, return sources as structured data in a response header (as shown in the query route above) and render them separately in the UI as a citation list.
How do I prevent the LLM from hallucinating answers not in my knowledge base?
The most reliable technique is a strict system prompt: "Answer only using the provided context. If the answer is not present, respond with: I don't have information on that topic." You can also add a similarity score threshold — if the top retrieved chunk scores below 0.75, skip the LLM call entirely and return a "no results" response.
Conclusion
You've now seen every layer of a production-grade AI knowledge base with Next.js and Sanity: from schema design and content ingestion, through vector indexing and semantic retrieval, to a streaming chat interface with source citations. The architecture is intentionally modular — swap Pinecone for pgvector, OpenAI for a self-hosted model, or the chat UI for a Slack bot, and the core pipeline stays the same.
The most important takeaway is that Sanity remains your source of truth. The vector index is a derived, queryable projection of your content — not a replacement for it. Keep your content well-structured, your webhooks reliable, and your chunking strategy tuned, and you'll have a knowledge base that genuinely helps users find answers instead of just searching for them.