Sanity
How to Build SEO-Friendly Blog Pages with Next.js and Sanity
Learn how to build SEO-friendly blog pages with Next.js and Sanity. Master GROQ queries, dynamic routing, metadata generation, Portable Text, and structured data.
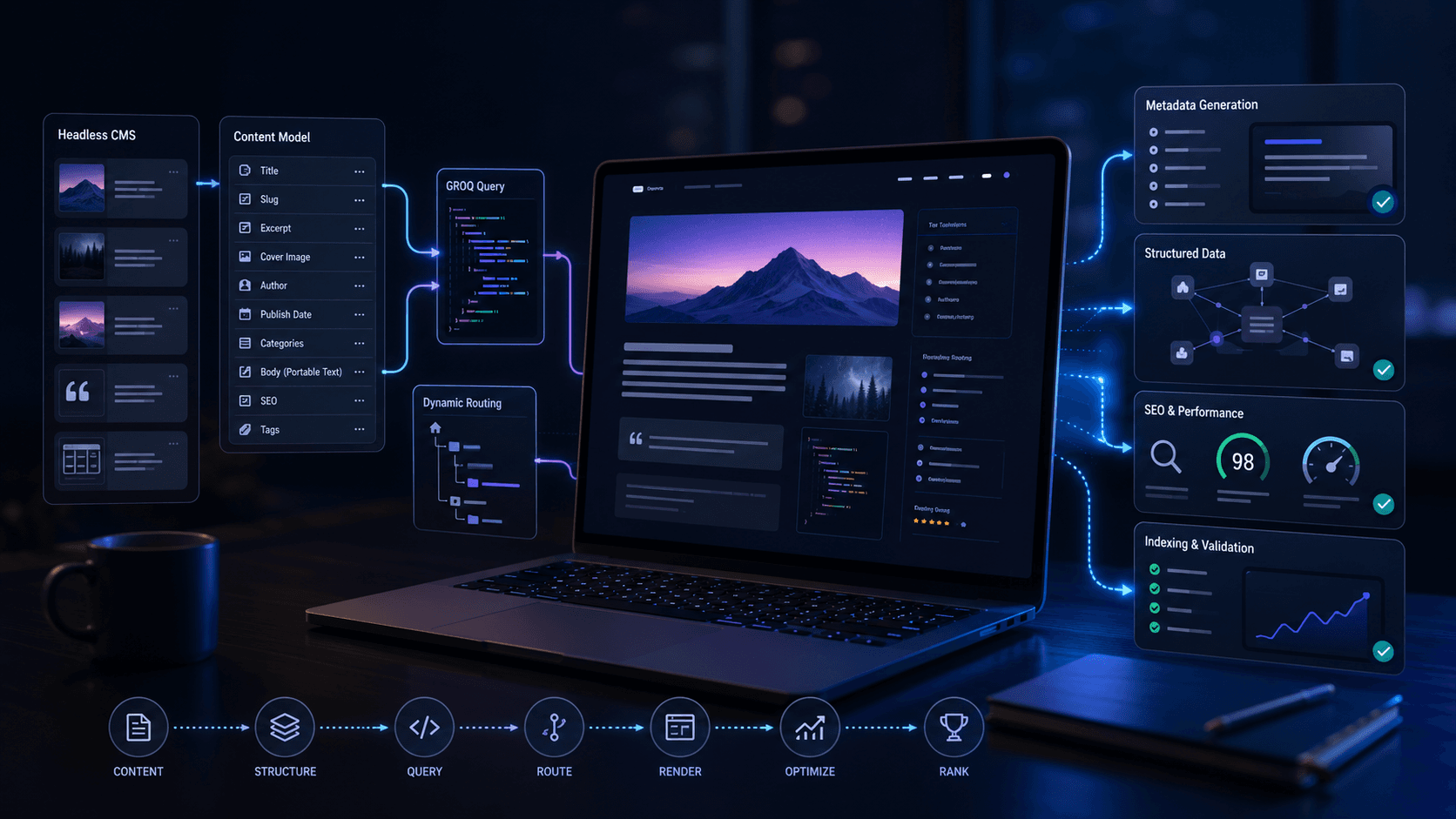
If you’re building a content-driven website, combining Next.js with Sanity is one of the most powerful stacks available today. But getting Next.js Sanity SEO right requires more than just rendering content — it means wiring up dynamic metadata, structured data, optimized images, and clean URLs from end to end. This tutorial walks you through every layer of the stack, from schema design to sitemap generation, so your blog ranks as well as it reads.
Setting up Sanity for a Blog
The foundation of any Sanity-powered blog is a well-designed schema. Start by defining a post document type in your Sanity Studio configuration.
Create a file at schemas/post.ts in your Studio project:
import { defineType, defineField } from 'sanity'
export const postType = defineType({ name: 'post', type: 'document', title: 'Blog Post', fields: [ defineField({ name: 'title', type: 'string', validation: Rule => Rule.required().max(100) }), defineField({ name: 'slug', type: 'slug', options: { source: 'title', maxLength: 96 } }), defineField({ name: 'excerpt', type: 'text', rows: 3 }), defineField({ name: 'mainImage', type: 'image', options: { hotspot: true }, fields: [{ name: 'alt', type: 'string', title: 'Alt text' }] }), defineField({ name: 'body', type: 'array', of: [{ type: 'block' }, { type: 'image' }] }), defineField({ name: 'publishedAt', type: 'datetime' }) ] })
Register this type in your sanity.config.ts by adding it to the schema.types array. For TypeScript support, run npx sanity@latest typegen generate to auto-generate types from your schema. This gives you fully typed GROQ query results throughout your Next.js app, eliminating a whole class of runtime errors.
Keep your Studio configuration lean: use groups to organise fields into Content, Taxonomy, and SEO tabs so editors can navigate large documents without scrolling endlessly.
GROQ Queries for Blog Post Data
GROQ (Graph-Relational Object Queries) is Sanity’s query language. It is expressive, fast, and purpose-built for content APIs. Here are the three queries you will use most often.
Fetch all posts for a listing page:
const ALL_POSTS_QUERY = groq\*[_type == “post” && defined(slug.current)] | order(publishedAt desc) { _id, title, slug, excerpt, publishedAt, mainImage { asset->, alt }, “author”: author->{ name, image } }``
Fetch a single post by slug:
const POST_BY_SLUG_QUERY = groq\*[_type == “post” && slug.current == $slug][0] { _id, title, slug, excerpt, body, publishedAt, mainImage { asset->, alt }, “author”: author->{ name, image }, “category”: category->{ title, slug } }``
Fetch related posts (same category, excluding current):
const RELATED_POSTS_QUERY = groq\*[_type == “post” && category._ref == $categoryId && slug.current != $currentSlug] | order(publishedAt desc) [0…2] { _id, title, slug, excerpt, mainImage { asset->, alt } }``
Always use the -> dereference operator to expand references inline. Avoid fetching the entire document when you only need a subset of fields — projections keep payloads small and responses fast. Use $params for all dynamic values to prevent injection and enable query caching.
Wrap your queries in a sanityFetch helper that sets perspective: 'published' in production and perspective: 'previewDrafts' when a draft mode cookie is present. This single pattern powers both your live site and your Studio live preview.
Dynamic Routing in App Router
Next.js App Router uses file-system conventions for dynamic routes. For a blog, create the file app/blog/[slug]/page.tsx.
The generateStaticParams function tells Next.js which slugs to pre-render at build time:
export async function generateStaticParams() { const slugs = await sanityFetch<{ slug: { current: string } }[]>({ query: groq\*[_type == “post” && defined(slug.current)]{ slug }` }) return slugs.map((post) => ({ slug: post.slug.current })) }`
The page component itself receives the slug as a prop:
export default async function BlogPostPage({ params }: { params: { slug: string } }) { const post = await sanityFetch<Post>({ query: POST_BY_SLUG_QUERY, params: { slug: params.slug } }) if (!post) notFound() return <article> <h1>{post.title}</h1> <PortableText value={post.body} /> </article> }
Set export const dynamicParams = false if you want a strict 404 for any slug not returned by generateStaticParams. For large blogs with thousands of posts, consider dynamicParams = true combined with revalidate so new posts go live without a full rebuild. Use next: { tags: ['post', post._id] } on your fetch calls and call revalidateTag from a Sanity webhook to get on-demand ISR.
Generating Metadata from Sanity Fields
Next.js App Router’s generateMetadata function is the correct place to set <title>, <meta name="description">, and Open Graph tags. Pull the values directly from Sanity:
export async function generateMetadata({ params }: { params: { slug: string } }): Promise<Metadata> { const post = await sanityFetch<{ title: string; excerpt: string; mainImage: SanityImage; seo: SeoFields }>({ query: POST_META_QUERY, params: { slug: params.slug } }) if (!post) return {} const ogImageUrl = post.seo?.openGraphImage ? urlFor(post.seo.openGraphImage).width(1200).height(630).url() : urlFor(post.mainImage).width(1200).height(630).url() return { title: post.seo?.title ?? post.title, description: post.seo?.description ?? post.excerpt, alternates: { canonical: post.seo?.canonicalUrl ?? \https://yourdomain.com/blog/${params.slug}\` }, openGraph: { title: post.seo?.title ?? post.title, description: post.seo?.description ?? post.excerpt, images: [{ url: ogImageUrl, width: 1200, height: 630 }], type: ‘article’, publishedTime: post.publishedAt }, twitter: { card: ‘summary_large_image’ } } }`
A few important details: always set a canonical URL to prevent duplicate-content penalties when the same post is accessible via multiple paths. Use @sanity/image-url to generate correctly sized OG images — a 1200×630 pixel image is the standard for Open Graph. Store SEO overrides in a dedicated seo object on the document so editors can fine-tune titles and descriptions without touching the main content fields.
Rendering Portable Text for SEO
Portable Text is Sanity’s rich-text format. The @portabletext/react package renders it in React, and custom components let you control the exact HTML output — which matters enormously for SEO.
Install the package: npm install @portabletext/react
Define custom components:
const portableTextComponents: PortableTextComponents = { types: { image: ({ value }) => ( <figure> <img src={urlFor(value).width(800).url()} alt={value.alt ?? ''} width={800} height={450} loading="lazy" /> {value.caption && <figcaption>{value.caption}</figcaption>} </figure> ) }, block: { h2: ({ children }) => <h2 id={slugify(children)}>{children}</h2>, h3: ({ children }) => <h3 id={slugify(children)}>{children}</h3>, blockquote: ({ children }) => <blockquote>{children}</blockquote> }, marks: { link: ({ value, children }) => ( <a href={value.href} rel={value.blank ? 'noopener noreferrer' : undefined} target={value.blank ? '_blank' : undefined}>{children}</a> ) } }
Always provide alt text for images — it is both an accessibility requirement and a ranking signal. Adding id attributes to headings enables anchor links and improves crawlability. Use loading="lazy" on body images but loading="eager" (or Next.js <Image priority>) on the hero image above the fold to protect your Largest Contentful Paint score.
Structured Data for Blog Articles
JSON-LD structured data helps search engines understand your content and can unlock rich results (article cards, breadcrumbs, author bylines) in the SERPs. Add a BlogPosting schema to every post page.
Create a <BlogPostingJsonLd> component:
export function BlogPostingJsonLd({ post }: { post: Post }) { const schema = { '@context': 'https://schema.org', '@type': 'BlogPosting', headline: post.title, description: post.excerpt, image: urlFor(post.mainImage).width(1200).url(), datePublished: post.publishedAt, dateModified: post.updatedAt ?? post.publishedAt, author: { '@type': 'Person', name: post.author.name }, publisher: { '@type': 'Organization', name: 'Your Site Name', logo: { '@type': 'ImageObject', url: 'https://yourdomain.com/logo.png' } }, mainEntityOfPage: { '@type': 'WebPage', '@id': \https://yourdomain.com/blog/${post.slug.current}\` } } return <script type=“application/ld+json” dangerouslySetInnerHTML={{ __html: JSON.stringify(schema) }} /> }`
Render this component inside your <article> element or directly in the page layout. Validate your output with Google’s Rich Results Test before deploying. Keep dateModified accurate — update it in Sanity whenever you make meaningful edits to a post, not just cosmetic ones.
Sitemap Generation
A sitemap tells search engines which URLs exist on your site and when they were last modified. With Next.js App Router, you can generate a dynamic sitemap by creating app/sitemap.ts:
import { MetadataRoute } from 'next' import { sanityFetch } from '@/sanity/lib/fetch' import { groq } from 'next-sanity' export default async function sitemap(): Promise<MetadataRoute.Sitemap> { const posts = await sanityFetch<{ slug: { current: string }; _updatedAt: string }[]>({ query: groq\*[_type == “post” && defined(slug.current)]{ slug, _updatedAt }`, tags: [‘post’] }) const postEntries = posts.map((post) => ({ url: `https://yourdomain.com/blog/${post.slug.current}\`, lastModified: new Date(post._updatedAt), changeFrequency: ‘weekly’ as const, priority: 0.8 })) return [ { url: ‘https://yourdomain.com’, lastModified: new Date(), priority: 1.0 }, { url: ‘https://yourdomain.com/blog’, lastModified: new Date(), priority: 0.9 }, …postEntries ] }`
This approach is zero-dependency and fully integrated with Next.js caching. Alternatively, use the next-sitemap package if you need an XML sitemap file on disk (useful for some CDN configurations). Submit your sitemap URL to Google Search Console and Bing Webmaster Tools after your first deployment.
Common Mistakes
Even experienced developers fall into these traps when building Next.js Sanity SEO setups:
- Missing alt text on images. Sanity image fields do not enforce alt text by default. Add a required
altstring field to every image type in your schema and validate it in the Studio. - No canonical URL. Without a canonical tag, Google may index both
/blog/my-postand/blog/my-post?ref=newsletteras separate pages, splitting link equity. - Blocking the Sanity CDN. Never add
X-Robots-Tag: noindexheaders to your Sanity API or CDN responses. Your Next.js pages are what need indexing, not the API. - Fetching full documents when only metadata is needed. Large GROQ projections slow down
generateMetadataand inflate your serverless function cold-start times. Use minimal projections for metadata queries. - Not revalidating on content changes. If you use
force-staticor longrevalidateintervals without a webhook, updated posts will not appear in search results until the next build. - Duplicate
<title>tags. Mixing<Head>fromnext/headwithgenerateMetadatain App Router causes duplicate tags. Use onlygenerateMetadatain App Router projects. - Ignoring Core Web Vitals. Unoptimised Portable Text images (missing
width/height, no lazy loading) tank your CLS and LCP scores, which directly affect rankings.
Best Practices
Follow these guidelines to get the most out of your Next.js Sanity SEO setup:
- Use
generateStaticParamsfor all known slugs so post pages are pre-rendered as static HTML, giving you the fastest possible TTFB. - Store SEO fields in a dedicated object (
seo.title,seo.description,seo.canonicalUrl,seo.openGraphImage) so editors can override defaults without touching body content. - Implement on-demand ISR with Sanity webhooks so published and updated posts appear on the live site within seconds, not hours.
- Use
next/imagefor all Sanity images to get automatic WebP conversion, responsivesrcset, and built-in lazy loading — all of which improve Core Web Vitals. - Add breadcrumb JSON-LD alongside your
BlogPostingschema to unlock breadcrumb rich results in Google Search. - Validate structured data regularly with Google’s Rich Results Test and Schema.org’s validator, especially after schema changes in Sanity.
- Monitor Search Console for crawl errors after deploying new slug patterns or redirecting old URLs, and use
next/headersto set proper301redirects for changed slugs.
FAQ
Q: Do I need a separate SEO plugin for Sanity Studio?
The official sanity-plugin-seo package adds a real-time SEO score panel to the Studio, which is helpful for content teams. However, it is optional — you can achieve excellent SEO purely through schema design and Next.js metadata generation without any plugin.
Q: How do I handle pagination for SEO?
Use numbered pages (/blog/page/2) rather than infinite scroll or query-string pagination. Add rel="prev" and rel="next" link tags (or include paginated URLs in your sitemap) so Google can discover all posts. Avoid ?page=2 query strings as canonical URLs.
Q: Should I use the Sanity CDN or the API directly?
Always use the CDN (useCdn: true) for published content in production. The CDN is globally distributed and dramatically faster than hitting the API directly. Only bypass the CDN for draft previews where you need the absolute latest unpublished content.
Q: How do I redirect old blog URLs after a slug change?
Store the old slug in a redirectFrom array field on the post document. In next.config.ts, fetch all redirect mappings from Sanity at build time and return them from the redirects() function. This keeps your redirect logic in the CMS where editors can manage it.
Q: Can I use Sanity’s AI Assist for SEO content generation?
Yes. Sanity AI Assist can auto-generate SEO titles, meta descriptions, and alt text based on your document content. Configure field-level instructions in your schema to guide the AI, then let editors review and refine the suggestions before publishing.
Conclusion
Building a high-performing blog with Next.js Sanity SEO is entirely achievable when you treat each layer — schema design, GROQ queries, dynamic routing, metadata, structured data, and sitemaps — as a first-class concern rather than an afterthought. The patterns in this guide give you a production-ready foundation: statically generated pages that revalidate on demand, rich metadata pulled directly from your CMS, and structured data that helps search engines surface your content to the right readers. Start with the schema, wire up generateMetadata, add your JSON-LD, and submit your sitemap. Your content deserves to be found.